
This is the part 1 of my series on deep reinforcement learning. See part 2 “Deep Reinforcement Learning with Neon” for an actual implementation with Neon deep learning toolkit.
Today, exactly two years ago, a small company in London called DeepMind uploaded their pioneering paper “Playing Atari with Deep Reinforcement Learning” to Arxiv. In this paper they demonstrated how a computer learned to play Atari 2600 video games by observing just the screen pixels and receiving a reward when the game score increased. The result was remarkable, because the games and the goals in every game were very different and designed to be challenging for humans. The same model architecture, without any change, was used to learn seven different games, and in three of them the algorithm performed even better than a human!
It has been hailed since then as the first step towards general artificial intelligence – an AI that can survive in a variety of environments, instead of being confined to strict realms such as playing chess. No wonder DeepMind was immediately bought by Google and has been on the forefront of deep learning research ever since. In February 2015 their paper “Human-level control through deep reinforcement learning” was featured on the cover of Nature, one of the most prestigious journals in science. In this paper they applied the same model to 49 different games and achieved superhuman performance in half of them.
Still, while deep models for supervised and unsupervised learning have seen widespread adoption in the community, deep reinforcement learning has remained a bit of a mystery. In this blog post I will be trying to demystify this technique and understand the rationale behind it. The intended audience is someone who already has background in machine learning and possibly in neural networks, but hasn’t had time to delve into reinforcement learning yet.
The roadmap ahead:
- What are the main challenges in reinforcement learning? We will cover the credit assignment problem and the exploration-exploitation dilemma here.
- How to formalize reinforcement learning in mathematical terms? We will define Markov Decision Process and use it for reasoning about reinforcement learning.
- How do we form long-term strategies? We define “discounted future reward”, that forms the main basis for the algorithms in the next sections.
- How can we estimate or approximate the future reward? Simple table-based Q-learning algorithm is defined and explained here.
- What if our state space is too big? Here we see how Q-table can be replaced with a (deep) neural network.
- What do we need to make it actually work? Experience replay technique will be discussed here, that stabilizes the learning with neural networks.
- Are we done yet? Finally we will consider some simple solutions to the exploration-exploitation problem.
Reinforcement Learning
Consider the game Breakout. In this game you control a paddle at the bottom of the screen and have to bounce the ball back to clear all the bricks in the upper half of the screen. Each time you hit a brick, it disappears and your score increases – you get a reward.
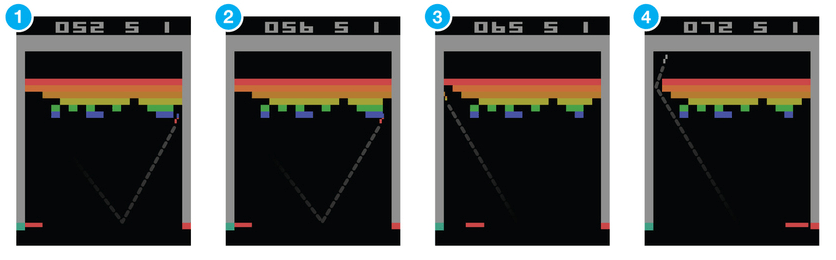
Suppose you want to teach a neural network to play this game. Input to your network would be screen images, and output would be three actions: left, right or fire (to launch the ball). It would make sense to treat it as a classification problem – for each game screen you have to decide, whether you should move left, right or press fire. Sounds straightforward? Sure, but then you need training examples, and a lots of them. Of course you could go and record game sessions using expert players, but that’s not really how we learn. We don’t need somebody to tell us a million times which move to choose at each screen. We just need occasional feedback that we did the right thing and can then figure out everything else ourselves.This is the task reinforcement learning tries to solve. Reinforcement learning lies somewhere in between supervised and unsupervised learning. Whereas in supervised learning one has a target label for each training example and in unsupervised learning one has no labels at all, in reinforcement learning one has sparse and time-delayed labels – the rewards. Based only on those rewards the agent has to learn to behave in the environment.While the idea is quite intuitive, in practice there are numerous challenges. For example when you hit a brick and score a reward in the Breakout game, it often has nothing to do with the actions (paddle movements) you did just before getting the reward. All the hard work was already done, when you positioned the paddle correctly and bounced the ball back. This is called the credit assignment problem – i.e., which of the preceding actions were responsible for getting the reward and to what extent.Once you have figured out a strategy to collect a certain number of rewards, should you stick with it or experiment with something that could result in even bigger rewards? In the above Breakout game a simple strategy is to move to the left edge and wait there. When launched, the ball tends to fly left more often than right and you will easily score on about 10 points before you die. Will you be satisfied with this or do you want more? This is called the explore-exploit dilemma – should you exploit the known working strategy or explore other, possibly better strategies.
Reinforcement learning is an important model of how we (and all animals in general) learn. Praise from our parents, grades in school, salary at work – these are all examples of rewards. Credit assignment problems and exploration-exploitation dilemmas come up every day both in business and in relationships. That’s why it is important to study this problem, and games form a wonderful sandbox for trying out new approaches.
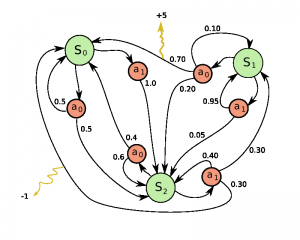
Markov Decision Process
Now the question is, how do you formalize a reinforcement learning problem, so that you can reason about it? The most common method is to represent it as a Markov decision process.
Suppose you are an agent, situated in an environment (e.g. Breakout game). The environment is in a certain state (e.g. location of the paddle, location and direction of the ball, existence of every brick and so on). The agent can perform certain actions in the environment (e.g. move the paddle to the left or to the right). These actions sometimes result in a reward (e.g. increase in score). Actions transform the environment and lead to a new state, where the agent can perform another action, and so on. The rules for how you choose those actions are called policy. The environment in general is stochastic, which means the next state may be somewhat random (e.g. when you lose a ball and launch a new one, it goes towards a random direction).